ラズパイでディープラーニング:交通標識認識プログラム例

前回のブログでは、ラズパイが持っているフォント数字を学習させることで、かなり高い精度でパソコンのフォント印字数字を認識する学習プログラムを紹介した。今度は、交通標識を機械学習することを試みた。交通標識は、形状が、円、四角、三角に分けられ、同じ形状でも、色が異なり、数字が記されていることもある。フォント数字の学習方法で使った白黒の二値画像ではなく、RGBのカラー画像で学習する方が、認識率が高まるはず。今回、カラーの交通標識を機械学習して、交通標識を認識するプログラムを作成したので、その手順を記録に残すことにした。
この結果は、ラズマウスが交通標識を認識し、その指示に従って走行するプログラムに応用できる。
●完成したラズパイで学習した交通標識認識事例
ラズパイにWEBカメラを接続して、「D」キーを押した時にキャプチャした画像を認識プログラムで交通標識を認識する。この事例は、CNN(Convolution Neural Network)モデルで学習したプログラムで認識したもの。標識は25mm(W) x 25mm(H)で、交通標識画像をプリンターで印刷し、その標識を抽出(ブルーで外形輪郭)して、CNNモデルで標識を認識して、その結果を表示した。以下に、交通標識の選択、標識サンプルの作成、学習モデルの作成(CNN)、認識プログラム事例について記載する。

●ラズパイのプログラム環境
深層学習(ディープラーニング)のプログラムを作る時に必要なモジュールをインストールする必要があるが、今回はRaspberry Pi 4BにフルセットでRaspberry Pi OSをインストールし、必要なモジュールTensorflow, Keras, sklearn, OpenCVをインストールした。最新のTensorflowにはKerasが含まれているが、ここでは単独Kerasをインストールして使った。
<使用したラズパイ>
Raspberry Pi 4B(4GB) :MicroSDHC(32GB)、Raspberry Pi OS
<各モジュールのバージョン>
Tensorflow : 1.14.0 (tensorflow.keras : 2.2.4 tf)
Keras : 2.3.1
OpenCV : 3.2.0
●交通標識認識の学習ステップ
(1)WEBサイトから認識に使える交通標識画像を選択
(2)学習用交通標識の作成
(3)学習モデルの構築と保存
(4)学習モデルを使った交通標識の認識
●WEBサイトから認識に使える交通標識画像を選択
WEBサイトから適当な交通標識画像をダウンロード。ダウンロードした11枚の画像のサイズは異なっているので、50 x 50 pixelのサイズにそろえ、標準の交通標識画像とした。フォントと異なり形状の異なる交通標識はないので、縦と横をそれぞれ100%~50%に圧縮し変形した標準画像を作成。
<11種類の50 x 50 pixelの標準の交通標識画像>

<標準交通標識を縦横に圧縮した標識のサンプル>
これで231の標準サンプル画像が得られた(./pictureDXフォルダーに保存)
●学習用交通標識の作成
50 x 50 pixelの学習用の交通標識画像データを作る。標準サンプル画像はが231枚しかないので、それぞれを回転、拡大・縮小の画像処理を施して、学習データを水増しし、データを”./image/SignImage.npz”に保存。サンプルデータ数は19404となった。
<水増ししたサンプル標識画像>ランダムにピックアップ
<プログラム例>RasSignSampleCreate.py
# -*- coding: utf-8 -*-
# 基本図形の交通標識: ./pictureSTD/*.png 11枚(50 x 50 pix)
# 基本図形の道路標識を、横方向に圧縮、縦方向に圧縮した変形図形を作成
# 画像サンプルを多くするため、回転、拡大で水増しする
# サンプル画像を出力するフォルダは、"./image/sign"(ランダムに抜き取り)
# データは、"./image/RasSignImg.npz"に保存
import os, glob
from PIL import Image, ImageDraw, ImageFont
import numpy as np
import cv2, random
import time
def transDX(signList):
# 変形した標準画像を出力するフォルダ
if not os.path.exists("./pictureDX"):
os.makedirs("./pictureDX")
for no, fname in enumerate(signList):
signName = os.path.basename(fname) # フォルダー名無しにする
signName = signName[:-4] # 拡張子除き
classNo = int(signName[:2]) # 先頭2文字がクラス番号
signImg = cv2.imread(fname) #BGR/ndarray ファイル名はフルネームで指定
baseH, baseW = signImg.shape[:2] #入力画像のサイズ
fname = "./pictureDX/{}-ORG.png".format(signName) # 標準図形も./pictureDX/に保存
cv2.imwrite(fname, signImg) # BGR(ndarray)
# 標準図形の標識の変形(横、縦を圧縮)
for sc in range(5, 55, 5): #0% ~ 50%圧縮
signImgDX = cv2.resize(signImg, (int(baseW * (100 - sc) / 100), baseH)) # ndarray
signH, signW = signImgDX.shape[:2]
wx = (baseW - signW) // 2
signImgX = np.full((baseH, baseW, 3), 255, dtype=np.uint8) # 白の正方形(H=ww,W=ww, color=3)画像をつくる。
signImgX[:, wx:wx+signW] = signImgDX # 中央に標識画像をコピー
fname = "./pictureDX/{}-X{}.png".format(signName, sc)
cv2.imwrite(fname, signImgX) # BGR(ndarray)
signImgDY = cv2.resize(signImg, (baseW, int(baseH * (100 - sc) / 100)))
signH, sjgnw = signImgDY.shape[:2]
wy = (baseH - signH) // 2
signImgY = np.full((baseH, baseW, 3), 255, dtype=np.uint8) # 白の正方形(H=ww,W=ww, color=3)画像をつくる。
signImgY[wy:wy+signH, :] = signImgDY # 中央に標識画像をコピー
fname = "./pictureDX/{}-Y{}.png".format(signName, sc)
cv2.imwrite(fname, signImgY) # BGR(ndarray)
def sampleCreate(signDxList, imageSize):
# 水増し変形標識画像の作成
X, Y = [], []
if not os.path.exists("./image/sign"): # ランダムに選んだサンプル画像を保存
os.makedirs("./image/sign")
seqNo = list(range(len(signDxList)))
random.shuffle(seqNo) # 変形した図形の並びをシャッフル
for no, picNo in enumerate(seqNo):
fname = signDxList[picNo]
signName = os.path.basename(fname)
classNo = int(signName[:2])
signImg = cv2.imread(fname) # ndarray(GBR)
# 回転、縮小/拡大する:PIL画像で行うため、ndarray->PILに変換
baseImg = Image.fromarray(np.uint8(signImg)) # numpy 配列画像を、PIL画像に変換
for ang in range(-20, 22, 2): # 回転-20, -18,....0, ...18, 20deg
subImg = baseImg.rotate(ang, fillcolor=(255, 255, 255)) #回転後の隙間を白にする
data = np.asarray(subImg) # asarrayなので、data = subImgとなる
X.append(data)
Y.append(classNo)
w = imageSize
for ratio in range(8, 15, 3): # 縮小・拡大する(70%, 100%, 130% , 160%)
size = round((ratio/10) * imageSize)
img2 = cv2.resize(data, (size, size), cv2.INTER_AREA)
data2 = np.asarray(img2)
if imageSize > size: # 変形画像が小さい時は空白画像の中心にコピー
x = (imageSize - size) // 2
data = np.full((imageSize, imageSize, 3), 255, dtype=np.uint8) # 白の正方形(H=ww,W=ww, color=3)画像をつくる。
data[x:x+size, x:x+size] = data2
else: # 変形画像が大きい時は、変形画像から定型サイズを切り抜く
x = (size - imageSize) // 2
data = data2[x:x+w, x:x+w]
X.append(data)
Y.append(classNo)
# 参考にサンプリングで画像データを保存(400回に1回)
if random.randint(0, 400) == 0:
fname = "image/sign/{0}({1})({2})({3}).png".format(signName[:-4], classNo, ang, ratio)
cv2.imwrite(fname, data)
return X, Y
"""メイン関数"""
if __name__ == '__main__':
# サイズの指定
imageSize = 50 # 50x50
# 標準標識の画像(50x50pixel)ファイルリスト。ファイル名={クラス番号}{標識名}-STD.png
signList = glob.glob("./pictureSTD/*.png")
transDX(signList) # 縦・横を#0% ~ 50%圧縮
# 変形を含めた図形を、回転、縮小・拡大で水増しして、X、Yに加える
signDxList = glob.glob("./pictureDX/*.png") # 変形した図形 リスト
X, Y = sampleCreate(signDxList, imageSize)
X = np.array(X)
Y = np.array(Y)
np.savez("./image/RasSignImg.npz", x=X, y=Y)
print("ok,", len(Y))
●学習モデルの構築と保存
CNNの学習モデルを構築し、モデルを“RasSignModelCNN_1.h5”のファイル名で保存した。このモデル構築にあたって、「Pythonで動かして学ぶ!あたらしい機械学習の教科書(伊藤真著)翔泳社」を参考にした。
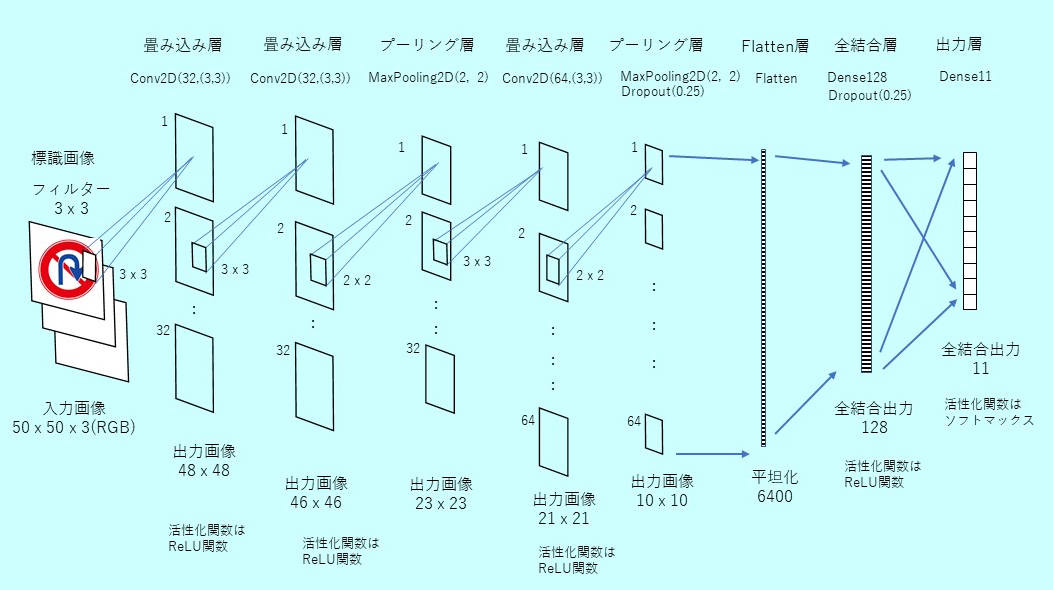
1層目、2層目は畳み込み層、3層目はマックスプーリング層、4層目は畳み込み層、5層目でマックスプーリング層を入れ、6層目はFlattenで6400個に平坦化、7層目で128個の全結合、最後の8層目は出力が11個の全結合層となる。データは訓練用14553個、検証用4851個
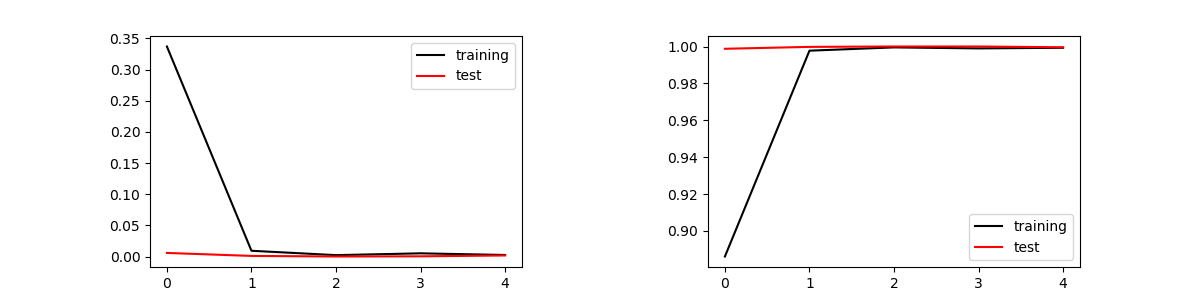
ラズパイではこの計算に約30分かかった。同じプログラムをWindows10 PCで走らせると、古いPC(Intel-i7:4core)でも3分程度で完了した。エポックが5で収束し正答率は99.96%となった。保存された次の学習モデルファイルを使って、文字認識を実行する。
(CNN文字認識学習モデルファイル)RasSignModelCNN_1.h5
<プログラム例>RasLearnSignCNN.py
# -*- coding: utf-8 -*-
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD, Adam, RMSprop
from keras.utils import np_utils
from sklearn import model_selection
import numpy as np
import time
import os
imgW, imgH = 50, 50
nClass = 11
def buildModelCNN():
# CNNのモデルを構築
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(imgW, imgH, 3), activation='relu'))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(nClass, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
return model
if __name__ == '__main__':
import matplotlib.pyplot as plt
signFileName = "./image/RasSignImg.npz"
if not os.path.exists(signFileName):
print("Sign File does not exist")
exit()
saveModelFile = "./RasSignModelCNN_1.h5"
sTime = time.time()
# フォント画像のデータを読む
xy = np.load(signFileName)
X = xy["x"]
Y = xy["y"]
# データを正規化
X = X.reshape(X.shape[0], imgW, imgH, 3).astype('float32')
X /= 255
Y = np_utils.to_categorical(Y, nClass)
# 訓練データとテストデータに分割
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, Y)
# モデルを構築
model = buildModelCNN()
history = model.fit(X_train, y_train,
batch_size=128, epochs=5, verbose=1,
validation_data=(X_test, y_test))
# モデルを保存
model.save(saveModelFile)
model.summary()
# モデルを評価
score = model.evaluate(X_test, y_test, verbose=0)
print("Test Loss = {}, Test Accuracy = {}".format(score[0], score[1]))
print('Conputation Time = ', time.time() - sTime)
# 学習過程をグラフ化
plt.figure(1, figsize = (12, 3))
plt.subplots_adjust(wspace=0.5)
plt.subplot(1,2,1)
plt.plot(history.history['loss'], 'black', label='training')
plt.plot(history.history['val_loss'], 'red', label='test')
plt.legend()
plt.subplot(1,2,2)
plt.plot(history.history['accuracy'], 'black', label='training')
plt.plot(history.history['val_accuracy'], 'red', label='test')
plt.legend()
plt.show()
<実行結果>
Train on 14553 samples, validate on 4851 samples Epoch 1/5 14553/14553 [==============================] - 360s 25ms/step - loss: 0.3371 - accuracy: 0.8861 - val_loss: 0.0059 - val_accuracy: 0.9988 Epoch 2/5 14553/14553 [==============================] - 375s 26ms/step - loss: 0.0093 - accuracy: 0.9977 - val_loss: 0.0011 - val_accuracy: 0.9998 Epoch 3/5 14553/14553 [==============================] - 376s 26ms/step - loss: 0.0023 - accuracy: 0.9995 - val_loss: 1.2406e-04 - val_accuracy: 1.0000 Epoch 4/5 14553/14553 [==============================] - 376s 26ms/step - loss: 0.0052 - accuracy: 0.9990 - val_loss: 4.1104e-04 - val_accuracy: 1.0000 Epoch 5/5 14553/14553 [==============================] - 376s 26ms/step - loss: 0.0026 - accuracy: 0.9993 - val_loss: 0.0018 - val_accuracy: 0.9996 Test Loss = 0.0017822985765753151, Test Accuracy = 0.9995877146720886 Conputation Time = 1899.2608473300934
<Model Summary>
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 48, 48, 32) 896 _________________________________________________________________ conv2d_1 (Conv2D) (None, 46, 46, 32) 9248 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 23, 23, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 21, 21, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 10, 10, 64) 0 _________________________________________________________________ dropout (Dropout) (None, 10, 10, 64) 0 _________________________________________________________________ flatten (Flatten) (None, 6400) 0 _________________________________________________________________ dense (Dense) (None, 128) 819328 _________________________________________________________________ dropout_1 (Dropout) (None, 128) 0 _________________________________________________________________ dense_1 (Dense) (None, 11) 1419 ================================================================= Total params: 849,387 Trainable params: 849,387 Non-trainable params: 0
●CNN学習モデルを使った標識認識
ラズパイにUSB接続WEBカメラ(BSWHD06M:バッファロー製, 120万画素)を取付けOpenCVのビデオキャプチャで画像を取り込んだ。取り込んだ画像は、640 x 480 pixel。認識する標識は、25mm(W) x 25mm(H)の白い紙にプリンターでカラー印刷。問題は標識の外側輪郭をOpenCVで抽出する方法である。
<プログラムの構成>
(1)keras.modelsのload_modelでCNN学習モデルファイルを読み込む
RasSignModelCNN_1.h5
(2)カメラでキャプチャした画像から標識外形輪郭を抽出
(3)キャプチャ画像の中から標識の輪郭を抽出し、標識学習モデルで標識名を認識し表示
<プログラム例>RasRecogSign.py
# -*- coding: utf-8 -*-
import numpy as np
import cv2
from operator import itemgetter # sortのため
from keras.models import load_model
import os, glob
saveModelFile = "./RasSignModelCNN_1.h5"
model = load_model(saveModelFile)
font = cv2.FONT_HERSHEY_SIMPLEX
cap = cv2.VideoCapture(0)
def transImage(imgColor):
imgGray = cv2.cvtColor(imgColor, cv2.COLOR_BGR2GRAY) # 入力画像をグレースケール化
imgGray = cv2.GaussianBlur(imgGray, (5, 5), 0) # 5x5のgaussianフィルターでノイズ抑制
imgThresh = cv2.adaptiveThreshold(imgGray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY, 11, 2) # アダプティブ二値化
return imgGray, imgThresh
def detectSignFromThresh(imgThresh):
imgR, imgC = imgThresh.shape[:2]
imgThresh, contours, hierarchy = cv2.findContours(imgThresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
wjMin, hjMin = 50, 50 #最小文字サイズ
signCont=[] # parentがなく、childがあるcontoursのリスト
signRectList = [] # 選択された標識外形座標リスト
if len(contours) > 0:
for i in range(len(contours)):
parentNo = hierarchy[0][i][3] # 0:Next, 1:Prev, 2:Child, 3:Parent
childNo = hierarchy[0][i][2]
if parentNo != -1 and childNo > 0: # parentがなく、childがある輪郭を選択
signCont.append([contours[i], hierarchy[0][i]])
for i in range(len(signCont)):
cont = signCont[i][0]
(xj, yj, wj, hj) = cv2.boundingRect(cont) #(x, y , w, h) = 外接矩形の座標を示すタプル。 座標のデータの型はint
if wj >= wjMin and hj >= hjMin: # エリアがwjMin x hjMin より大きいならOK(小さなノイズを除去)
ptj1 = (xj, yj)
ptj2 = (xj + wj, yj + hj)
signRectList.append([i, [ptj1, ptj2], cont])
noRect = len(signRectList)
rectDelNo = []
statJ = False
for i in range(noRect): # 入れ子になっている輪郭は除外
statJ = False
no1, [pti1, pti2], cont = signRectList[i]
dx = (pti2[0] - pti1[0]) * 0.3
dy = (pti2[1] - pti1[1]) * 0.3
for j in range(noRect):
if i == j:
continue
no2, [ptj1, ptj2], cont = signRectList[j]
statJ = False
if (pti1[0] - dx) <= ptj1[0] and ptj1[0] <= pti1[0]: # pxi - dx < pxj < pxi
if (pti1[1] - dy) <= ptj1[1] and ptj1[1] <= pti1[1]: # pyi - dy < pyj < pyi
if pti2[0] <= ptj2[0] and ptj2[0] <= (pti2[0] + dx): # pxi < pxj < pxi + dx
if pti2[1] <= ptj2[1] and ptj2[1] <= (pti2[1] + dy): # pyi < pyj < pyi + dy
statJ = True # jが親だった場合、検索終了
break
if statJ == True: # 親があった場合、削除リストにiを追加
rectDelNo.append(i)
rectDelNo.reverse() # 後から順に削除
for i in range(len(rectDelNo)):
del signRectList[rectDelNo[i]]
return contours, signRectList
def makeAImgColor(imgColor, pt):
pt1, pt2 = pt
if ((pt2[1] - pt1[1]) > 0) and ((pt2[0] - pt1[0]) > 0):
imgCrop = imgColor[pt1[1] : pt2[1], pt1[0] : pt2[0]] # [row1 : row2, col1 : col2]
w = pt2[0] - pt1[0]
h = pt2[1] - pt1[1]
ww = round(max(w, h) * 1.1) # w, hの大きい方の長さwwで正方形画像、余白10%
spc = np.full((ww, ww, 3), 255, dtype=np.uint8) # 画像を白に
wy = (ww-h)//2 #高さ方向の余白を計算
wx = (ww-w)//2 #幅方向の余白を計算
spc[wy:wy+h, wx:wx+w, :] = imgCrop # 余白の内側に標識画像を入れる
img50x50 = cv2.resize(spc, (50, 50)) # 50 x 50サイズに揃える
imgAI = img50x50.astype("float32") / 255 # CNNの場合、入力画像は50x50x3(GBR)
statOK = True
else:
imgAI = imgColor.copy()
statOK = False
return statOK, imgAI
def recognizeSign(imgAI):
probArray = model.predict(np.array([imgAI])) # 入力はimgのリスト、1個だけなので[imgAI]
result = probArray.argmax() # probArray(np.array)の 最大値のindex(0-10)が検出標識
prob = probArray.max() # 検出標識の確率
return result, prob
def getSignName(signList):
signDict = {}
for no, fname in enumerate(signList):
signName = os.path.basename(fname) # フォルダー名無しにする
classNo = int(signName[:2]) # 先頭2文字がクラス番号
signName = signName[2:-8] # Sign名の取り出し(クラス番号、'-STD.png' 除去)
signDict [classNo] = signName
return signDict
def drawResult(allContours, signRectList, recogSignList, imgColor, imgThresh):
rgbIm = imgThresh.copy()
imgThreshColor = cv2.merge((rgbIm, rgbIm, rgbIm)) # 二値化画像をRGBに
imgThreshColor = cv2.drawContours(imgThreshColor, allContours, -1, (0,255,0), 1) # 全ての輪郭を「グリーン」で描画
for i in range(len(recogSignList)): # 検出したサイン
signNo, signIndex, signName, prob = recogSignList[i]
contNo, [pt1, pt2], cont = signRectList[signNo]
(xb, yb) = pt1
pttxt = (xb, yb-10)
pttxt2 = (xb-20, yb-10)
signNoName = str(signIndex) + ":" + signName
cv2.putText(imgColor, signNoName, pttxt, font, 0.5, (0, 255, 255), 1, cv2.LINE_AA, False) # クラス番号と認識標識名を表示
cv2.rectangle(imgColor, pt1, pt2, (255, 255, 0), 2) # 検出サイン外形矩形をブルーで囲む
cv2.rectangle(imgThreshColor, pt1, pt2, (255, 255, 0), 2) # 検出サイン外形矩形をブルーで囲む
cv2.namedWindow('Result', cv2.WINDOW_AUTOSIZE)
cv2.imshow('Result',imgColor)
cv2.moveWindow('Result', 500,0)
cv2.namedWindow('imgThreshColor', cv2.WINDOW_AUTOSIZE)
cv2.imshow('imgThreshColor',imgThreshColor)
cv2.moveWindow('imgThreshColor', 500, 540) #Display = 1920 x 1080
def contCheck(contNo, cont):
(xb, yb, wb, hb) = cv2.boundingRect(cont)
conArea = cv2.contourArea(cont) # 輪郭の面積計算(単位がピクセルではない)
#回転を考慮した外接矩形面積は実態に近い
rectR = cv2.minAreaRect(cont) # rectR : ((x,y), (w,h), angle) x,y,w,h,angleはfloat
box = cv2.boxPoints(rectR) # 4角のコーナーの座標
boxNP = np.int0(box) # 整数に。[[x1,y1],[x2,y2],[x3,y3],[x4,y4]]
conBoxArea = cv2.contourArea(boxNP) # 輪郭の面積計算 → 単位はピクセルではないので、w x hは使えない
stat = False if conArea / conBoxArea < 0.4 else True # 輪郭面積が計算上の矩形面積より小さい場合は対象外
return stat
"""メイン関数"""
if __name__ == '__main__':
import os, glob
iFlag = True
signList = glob.glob("./pictureSTD/*.png")
signDict = getSignName(signList) # 標準標識画像のファイル名から「クラス番号」と「標識名」を得る
while(iFlag):
ret, frame = cap.read()
cv2.namedWindow('VIDEO', cv2.WINDOW_AUTOSIZE)
cv2.imshow('VIDEO', frame)
cv2.moveWindow('VIDEO', 0, 540)
k = cv2.waitKey(1) & 0xFF
if k == ord('q'):
print("QUIT")
break
elif k == ord('d'): # 文字検出
imgGray, imgThresh = transImage(frame) # 解析用の画像変換
allContours, signRectList = detectSignFromThresh(imgThresh)
# allContours: 検出したすべての輪郭データ(原画に表示)
# signRectList = リスト[no, (p1x, p1y), contours]
recogSignList = []
if len(signRectList) > 0: # サインを1個以上検出した場合
for signNo in range(len(signRectList)):
contNo, [pt1, pt2], cont = signRectList[signNo]
if contCheck(contNo, cont): # contoursデータから標識らしさをチェック
statOK, imgAI = makeAImgColor(frame, [pt1, pt2]) # 認識する50x50のカラー画像に加工(imgAI)
if statOK:
signIndex, prob = recognizeSign(imgAI)
# signIndex:認識した標識index, prob:確率
print("Recognized Sign Index = ", signIndex, signDict[signIndex], prob)
recogSignList.append([signNo, signIndex, signDict[signIndex], prob])
else:
print("NG! 認識ラベル無し")
drawResult(allContours, signRectList, recogSignList, frame, imgThresh)
else:
continue
k = cv2.waitKey(0)
cap.release()
cv2.destroyAllWindows()
<実行結果>


<標識を認識のための画像処理>
まずはOpenCVを使い入力画像をグレースケール化、gaussianフィルターでノイズ抑制し、アダプティブ二値化を適用した。この二値画像では多くの輪郭が検出されるが、標識と他の画像を区別するため、50 x 50pixel以下の小さい輪郭は除去した。また標識の外側の二重線が輪郭として認識され、一つの標識に複数の輪郭が検出される(入れ子状態になる)ことがあり、この場合一番内側の輪郭だけを採用。標識の輪郭を検出するステップは次の通り。
①二値化後の画像から輪郭検出(階層情報付)
②輪郭階層で、親の輪郭を持たず、子の輪郭を持つ輪郭を選択
③上記①の中で、50 x 50 pixel以下の小さい輪郭(ノイズ)を除去
④上記②の中で、入れ子状態(同一の画像を示している輪郭)の外側輪郭を除去
CNN学習で認識した結果は黄色で「クラス番号」「標識名」を記した。今回の認識では、輪郭検出できれば、交通標識は100%の認識率となった。